St. George’s Hospital Medical School Admisson’s Algorithm
In the late 1970’s Dr. Geoffrey Franglen of St. George’s Hospital Medical School in London wrote an algorithm to assist the admission team with the admission process. The goal was to save time and make the entire process more efficient, as any algorithm’s goal is. The algorithm came into effect in the year 1982. Only after a few years staff of the school started to notice the lack of diversity among the student population. This is because the data that was fed to the algorithm showed favoritism towards Caucasian men. To be more specific the algorithm would essentially give a student ‘Points’ based on their information. It came to light that students would gain more points if they were; male, from London, and had a caucasian sounding name. This instance of algorithmic bias demonstrates unethical practice because it gives others an unfair advantage based off of their identity. Although the algorithm was not made with any ill intention, we could claim that this problem came to light because Dr. Geoffrey Franglen forgot to take into account the type of information that he was feeding into the algorithm. However, we can also claim that the function being performed by the admission algorithm is also at fault in this situation. Why is an algorithm giving points to students based on their gender, name, residential status? These are all irrelevant when measuring how a student will succeed if admitted into a school.
Commercial Gender Recognition Algorithm
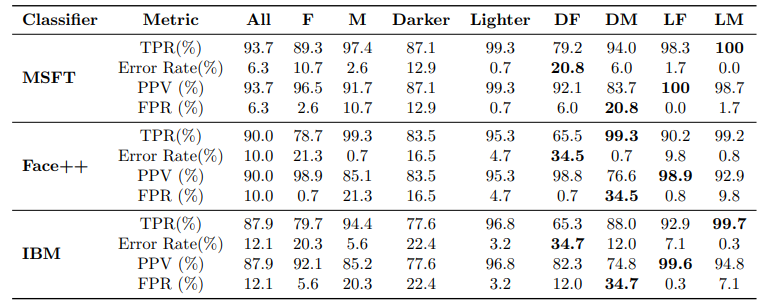
There is a paper called “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification” by Joy Buolamwini and Timnit Gebru (2018). This paper speaks on the author’s results of investigating the accuracy of commercial gender recognition algorithms. The main idea is that Buolamwini and Gebru took 1200 images of individuals from sources such as; the congressional biographical directory, the U.S. Department of State’s Visa and passport database, and Linkedin profiles of researchers that are involved in the computer vision field. They tested these 1200 images on three popularly used commercial gender recognition algorithms. Some of the results they found were that the accuracy rate was over 95% for lighter skinned males but there was an error rate of over 35% on darker skinned-females. You can find the table at the end of the page to see the results across different demographics. Some common usages of gender recognition algorithms are targeted advertising and for security surveillance. The issue in this case leans more towards security surveillance, as a 35% error rate has a higher chance of leading to recognizing the wrong individual. A hypothetical example would be if someone was to shoplift, big corporations such as Target and Walmart use this recognition algorithm to keep track of individuals who shoplift from them. This could lead to them identifying a wrong individual for committing a crime that they never did. This is another example of feeding an algorithm information that leads to unethical practice. This is definitely the fault of the software engineers who developed these various algorithms. When testing the algorithm this issue should have come to light.
Compas Algorithm
The COMPAS algorithm is used to assess potential risk of a defendant becoming a repeat offender. The algorithm has been adapted by many states. Four people; Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner decided to investigate this algorithm in Broward county, Florida. They analyzed over 7,000 defendants and found that black defendants had a higher chance of receiving a higher risk score. The risk score is what the algorithm produces after its assessment of an individual. It is a scale of 1-10, where a higher score means that a defendant has a higher risk of being a repeat offender. An example that shows unethical practices is that two men were arrested for drug possession, Dylan Fugett who had a prior offense of 1 attempted burglary and Bernard Parker who had a prior offense of resisting arrest without violence. Both these men are now repeat offenders, and once could argue that Dylan Fugett’s offenses are worse. However, he received a risk score of 3, and Bernard Parker received a score of 10. Dylan Fugett is a white man and Bernard Parker is a black man. Post this offense, Bernard does not have any subsequent offense although he was evaluated to have a very high risk of repeating, Dylan Fugett had 3 subsequent drug possession offenses. This algorithm fails to solely evaluate individuals based on their crime/criminal history, it instead seems to take race into account more than the actual criminal history. The study showed that black defendants were 77% more likely to be assigned a higher risk score than white defendants. This algorithm is not only the fault of the software engineer’s failing to separate one’s personal identity that they cannot control over the crimes they have committed, it is also the fault of the function being done by the algorithm. The functional issue here isn’t just that black defendant’s are receiving ridiculously higher scores for offenses that don’t indicate a higher risk, it is that if two individuals had identical criminal histories that they are not evaluated to have the same risk which in practicality they should.
It can be observed that most algorithmic bias can be fixed/reduced with being more conscious of what information us Software Engineers are feeding algorithms upon creation. Although some will argue that algorithms are not created with ill intent, it is our responsibility as the engineers to take into account the potential bias that could be performed. If anything a counter-argument is that although algorithms are not usually created with ill intent, it is our responsibility to take into account the algorithmic bias that can be performed as this potential bias is essentially an edge case.
Here is the results of Joy Buolamwini and Timnit Gebru research: