Kelly Duffy
2019-04-01
HRF-GIMME
HRF-GIMME is an extension of GIMME that allows for the modeling of task-related effects in fMRI using the hemodynamic response function (HRF). Use of HRF-GIMME enables the modeling of direct task effects as well as how the presence of a task may modulate the relations between brain regions. Doing so requires the modeling of the hemodynamic response function (HRF), a function that arrives at the expected psychophysiological response in the fMRI data (i.e. the expected BOLD signal that will be measured).
Previous research has demonstrated that the HRF varies more between individuals than between brain regions within an individual (Handwerker, Ollinger, & D’Esposito, 2004). For this reason HRF-GIMME provides individual estimates of the HRF. To do so, HRF-GIMME uses the smoothed finite impulse response function (sFIR; Gouette et al., 2000), a flexible basis set that is able to model the HRF with no assumptions about its shape, and has been shown to effectively model the HRF when there are individual variations in shape (Lindquist, 2009). The (binary) stimulus onset/task vector is then convolved with the individual HRF, allowing for the investigation of the direct effects of the task on the various brain regions. The multiplication of this convolved task vector with selected brain regions allows for the investigation of how the relations between brain regions may vary in the presence of a task. These modulatry effects in combination with the intrinsic connections among brain regions enables connectivity modeling with task-based data coming from event-related designs.
Note that while HRF-GIMME was designed with fMRI data in mind, the algorithm can be applied to examine the direct and modulating effects of any exogenous variable on a set of other variables that are coded with 0 or 1 (e.g. did a stressor occur) with a response curve of any shape, as HRF-GIMME makes no assumptions about the form.
Running HRF GIMME
To begin, we will load in simulated data with a task onset vector. This data has 25 people, each with 500 time points for 5 variables (4 brain regions and 1 task onset vector). This data is available as part of the GIMME package.
library(gimme)
data(HRFsim, package="gimme")I will now provide more details on the arguments relevant to HRF-GIMME. For further information on the other arguments, please see the GIMME vignette, or the documentation of the gimmeSEM function using
?gimme::gimmeSEM HRF-GIMME can be run on this simple example of simulated data with the code shown below:
HRF.fit <- gimme(data = HRFsim,
out = '~/outputfolder/',
ar = TRUE,
standardize = TRUE,
exogenous = "V5",
conv_vars = "V5",
conv_length = 16,
conv_interval = 1,
mult_vars = "V3*V5",
mean_center_mult = TRUE,
groupcutoff = .75)standardize: Whether all variables will be standardized to have a mean of zero and a standard deviation of one. We recommend setting standardize = TRUE so that all variables will be have the same variance. This prevents convergence issues that may occur from variables with large differences in variance (common when looking at BOLD versus HRF-convolved time courses).
exogenous: Vector of variable names to specify all exogenous variables (variables that can predict other variables, but cannot be predicted). Note that this should include any variables that will be convolved (e.g. the task onset vector), which are always exogenous. Note that exogenous variables are not lagged.
conv_vars: Vector of variable names to be convolved (e.g. the task onset vector) via the smoothed Finite Impulse Response (sFIR).
conv_length: The expected response length in seconds. Defaults to 16 seconds, which is typical for the HRF.
conv_intervals: Interval between data acquisition. For fMRI studies, this is the repetition time (TR). Currently must be a constant.
mult_vars: Vector of variable names to be multiplied to explore bilinear/modulatory effects. Within the vector, multiplication of the variables should be indicted with an asterisk. If a header is used, variables should be referred to by their variable names. If no header is used, variables should be referred to as V followed by the column number (as shown above). If lagged variables are desired, variable names can be appended with “lag”, no separation (e.g. “V3lag*V5“). Remember that exogenous/convolved variables are not lagged.
mean_center_mult: Logical indicating whether variables should be mean-centered before multiplication. We recommend setting mean_center_mult = TRUE, although the default is FALSE.
Output
Output of the GIMME object is not different from a standard GIMME object, except that multiplied variables are included and can be explored, named with “by” separating the variable names. A plot is shown below for illustration.
plot(HRF.fit)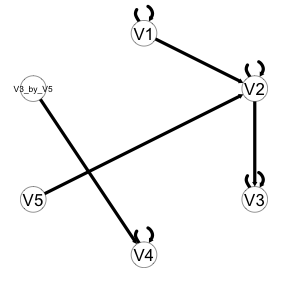
Here, we see that the relation between V3 and V4 is moderated by the exogenous variable (V5). This means that the relation between these two variables differs according to whether they are on or off task.