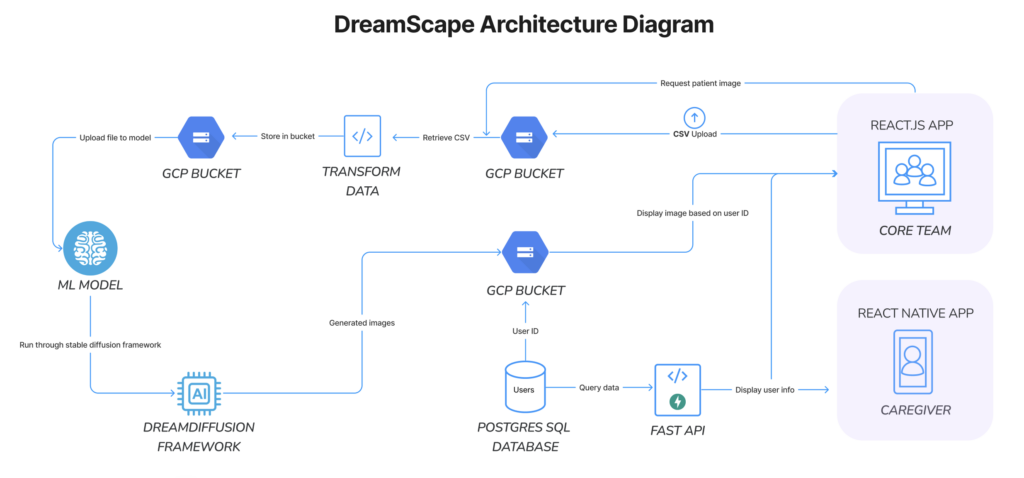
Architecture
Code Repository
Find it here
Detailed Data Definitions
User Database:
- id: an integer identifier for users that is automatically generated by the database
- Primary key
- first_name: a string with the user’s first name
- Can’t be null, will default to an empty string
- last_name: a string with the user’s last name
- Can’t be null, will default to an empty string
- device_id: an integer representation of a device id to associate a user with a specific device, allowing for device based authentication
- Must be unique
- dob: a string representing the user’s date of birth
- Can’t be null, will default to an empty string
- gender: a string with the user’s gender
Design Rationale: Design Decisions
Database:
The name, dob, and gender fields are included to have basic info that will allow admins to manually match data from our app to data they have on CareYaya servers, since our client told us that was their initial plan for using the app.
The device_id field exists to allow for device based authentication that the client expressed they wanted, so it made sense to include this field and have it be an index to increase search speed. API functions were made to search based on this for the same reason.
User Interfaces:
We’ve decided to have a React.js app for our CareYaya staff as they will mainly access the page from a desktop to view specific data. React.js keeps the interface very responsive and is compatible with multiple browsers, keeping in mind the different preferences the staff may have.
Our Caregiver app is a React Native application since most caregivers will want to access it while they are in patient homes, so it made sense to have in a mobile format. React Native is compatible with both iOS and Android devices, not limiting caregivers to a specific kind of device.
DreamDiffusion Framework:
Technology Stack
Programming Language: Python
Machine Learning Framework: PyTorch
Integration Framework: DreamDiffusion
System Dependencies
- DreamDiffusion Framework:
- Choice Rationale: Stakeholder preference and team proficiency in Python.
- Dependency: Python language.
- PyTorch Models:
- Choice Rationale: PyTorch’s seamless integration with Python as well as it being the model type of the original DreamDiffusion framework.
- Usage: The PyTorch models developed within the Dreamscape AI Module are primarily employed for making predictions based on the decoded EEG data.
- Dependency: GCP for hosting models but adaptable to other cloud services.
- Google Cloud Platform (GCP):
- Usage:
- Storage of large checkpoint files.
- Stroage of patient data (EEG brainwaves in CSV files, EEG signals saved in .pth files, etc).
- (Hopefully in the future) Hosting the model.
- Dependency: Initial reliance on GCP for specific features (buckets) and capabilities.
- Usage:
Development Decisions
- Preexisting Framework:
- Framework Choice: DreamDiffusion.
- Decision Rationale: Stakeholder preference and team familiarity with Python.
- EEG Data Processing:
- Integration: Muse SDK via Bluetooth.
- Decision Rationale: Real-time integration for processing EEG data.
Deployment Considerations
- GCP Hosting:
- Storage: GCS Buckets for storing patient’s brainwaves and large checkpoint files.
- Hosting Models: GCP’s platform for hosting and executing PyTorch models.
Additional Information
- DreamDiffusion Directory:
- File: requirements.txt
- Purpose: Lists Python dependencies for the DreamDiffusion framework.
- Flexibility:
- Adaptability: Although currently reliant on GCP, the AI module can be adapted to use other cloud services, ensuring flexibility for future changes.